
概述
Google工程师Jeffrey Dean 和 Sanjay Ghemawat在2004年发表了一篇论文MapReduce: Simplified Data Processing on Large Clusters,MapReduce作为大规模数据处理的需求下孕育而生的产物,被创造的初衷是为了解决Google公司内部搜索引擎中大规模数据的并行化处理。
引用维基百科中对MapReduce的介绍:
MapReduce是Google提出的一个软件架构,用于大规模数据集(大于1TB)的并行运算。
概念“Map(映射)”和“Reduce(归纳)”,及他们的主要思想,都是从函数式编程语言借来的,还有从矢量编程语言借来的特性。当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归纳)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
本系列将根据MIT6.824课程进行学习 MapReduce
简单看来,MapReduce的架构正如其名,分为Map和Reduce两部分。
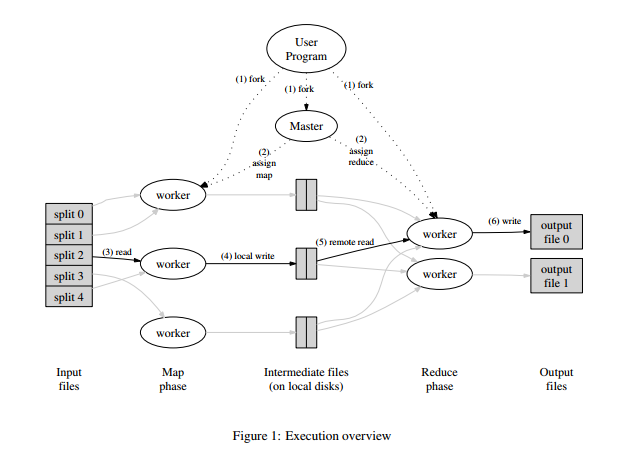
作为一个计算框架,其最大的核心便在于计算二字,以往处理计算的模式为单机运行,在大数据的情况下只能使用具有更强算力的计算机来完成计算工作,而算力的提升是需要花费极大的成本,这样在成本上是极为不划算的。在这一背景下MapReduce孕育而生,有个这样一个框架,就可以将数台不同算力的计算机组成一个集群,和适度的调度下并行计算提高效率降低成本。
根据上图,MapReduce中存在3中角色,Master,Worker(Map),Worker(Reduce),Master负责Map,Reduce两层的调度管理,Worker(Map)负责进行Map操作,Worker(Reduce)负责进行Reduce操作
现在以该课程lab1为例来进行细致的学习,整套课程将由Go语言来实现。
lab1主要是对MapReduce模型进行初步的学习,实现一个本机的MapReduce模型,完成对多个文件的词频统计。
示例程序流程
入口由上层程序控制,这个地方从master调度开始,预先定义Reduce任务个数m,再根据文本文件输入数量n。
master将n传递给doMap也就是Map调度层,告诉Map调度层执行n次Map计算,每个Map计算层对应输入各个文本文件的数据。
Map调度层将输出m*n个文件作为Map和Reduce的中间数据传递媒介,举例假设现在m为2、n为3,输出文件mid-0-0 mid-0-1 mid-1-0 mid-1-1 mid-2-0 mid-2-1这六个文件,其中mid-0-0 mid-0-1为第一个文本Map操作后的到的切分开的两个中间数据文件,剩下的以此类推。
在Reduce调度层中便会将这六个文件交由Reduce计算层处理,将件mid-0-0 mid-1-0 mid-2-0交由编号为0的Reduce计算任务处理,显然,编号为1的任务则负责剩下3个文件的规约操作。Reduce调度层中仍然会将每个Reduce计算层任务得到的数据分别存入文件,根据Reduce任务的数量m为2,则文件编号分别为res-0 res-1,这样Map、Reduce两种操作完成,但整个任务还为完成。
Merge操作则是最后一个步骤通常由master来完成,通过merge操作将上述的res-0 res-1合并,将所有结果存入到一个文件中,这样,整个MapReduce实现的多文本词频统计程序执行完毕。
数据结构
type KeyValue struct {
Key string
Value string
}
实现
Master调度
master.go
func (mr *Master) run(jobName string, files []string, nreduce int,
schedule func(phase jobPhase),
finish func(),
) {
mr.jobName = jobName
mr.files = files
mr.nReduce = nreduce
fmt.Printf("%s: Starting Map/Reduce task %s\n", mr.address, mr.jobName)
schedule(mapPhase) //map层进行操作
schedule(reducePhase) //reduce层进行操作
finish() //结束所有worker
mr.merge() //合并
fmt.Printf("%s: Map/Reduce task completed\n", mr.address)
mr.doneChannel <- true
}
这部分展示了master如何对map、reduce进行调度的过程,首先执行所有的map操作,执行完毕后执行所有的reduce操作进行规约,最后merge合并所有reduce之后的结果,把所有的结果汇总并存储。
Map调度层
common_map.go
func doMap(
jobName string, // MapReduce任务名
mapTaskNumber int, // Map任务序号
inFile string,
nReduce int, // Reduce Worker数量 ("R" in the paper)
mapF func(file string, contents string) []KeyValue,
) {
dat, err := ioutil.ReadFile(inFile) //读文本文件
if err != nil {
panic(err)
}
res := mapF(inFile, string(dat)) //根据文件中的内容进行单文件Map操作
m := make([]map[string]string, nReduce) //对于每个文本文件,将使用KeyValue的slice来存放,之后会对这部分数据进行切分,根据nReduce(reduce层worker数量)来决定划分数目
for _, kv := range res {
index := ihash(kv.Key) % nReduce //序号划分,根据Key做hash处理,对结果模你Reduce得到划分序号
if m[index] == nil{
m[index] = make(map[string]string)
}
m[index][kv.Key] = kv.Value
}
for i := 0; i < nReduce; i++ {
filename := reduceName(jobName, mapTaskNumber, i)
jsonObj, err := json.Marshal(m[i]) //使用json作为中间数据
if err != nil {
panic(err)
}
ioutil.WriteFile(filename, jsonObj, 0644) //将数据写入到文件中 //将json数据写入到文件中,供Reduce操作使用
}
Map调度层提供数据的输入与输出,不关心计算过程
Map计算层
wc.go
//filename 为输入文件文件名
//contents 为文本内容
func mapF(filename string, contents string) []mapreduce.KeyValue {
var res []mapreduce.KeyValue
m := make(map[string] int)
reg := regexp.MustCompile("\n|\r|\t|[ ]+|[\\-]+|\\(|\\)")
contents = reg.ReplaceAllString(contents," ")
reg = regexp.MustCompile("[^(a-zA-Z )]")
contents = reg.ReplaceAllString(contents,"")
//fmt.Println(contents)
s := strings.Split(contents," ")
for i := 0;i < len(s);i++ {
str := strings.TrimSpace(s[i])
m[strings.ToLower(str)]++
}
for k,v := range m{
val := strconv.Itoa(v)
res = append(res, mapreduce.KeyValue{k, val })
}
fmt.Println(res)
return res
}
Map计算层根据输入的文本内容完成下列步骤:
- 使用正则表达式将
\n\t\r替换为空格 - 使用正则表达式将无关字符删除
- 使用
strings.Split方法根据空格进行划分 - 取出划分后的每个词,使用
strings.TrimSpace方法去除两端空格,使用map[string] int结构的m来完成统计 - 将
map[string] int转换为[]KeyValue返回
Map计算层和Map调度层共同组成的Map的结构,一个负责计算,一个负责IO,分工明确
Reduce调度层
common_reduce.go
func doReduce(
jobName string, // MapReduce任务名
reduceTaskNumber int, // Reduce任务序号
outFile string, // 输出文件路径
nMap int, // Map任务数 ("M" in the paper)
reduceF func(key string, values []string) string,
) {
m := make(map[string][]string)
for i := 0; i < nMap; i++ {
filename := reduceName(jobName, i, reduceTaskNumber)
fmt.Println(filename)
data, err := ioutil.ReadFile(filename)
if err != nil {
panic(err)
}
var tm map[string]string
err = json.Unmarshal(data, &tm)
if err != nil {
panic(err)
}
for k, v := range tm {
if err != nil {
panic(err)
}
m[k] = append(m[k], v)
}
}
dataM := make([]KeyValue,0)
for k, v := range m {
ans := reduceF(k, v)
dataM = append(dataM, KeyValue{k,ans})
}
jsonData, err := json.Marshal(dataM)
if err != nil {
panic(err)
}
ioutil.WriteFile(outFile, jsonData, 0644)
}
Reduce调度层完成的工作是将Map执行后的文件读入为数据交有Reduce来规约,同样也不负责Reduce具体的过程,仅负责数据的读入(文件读入)和数据的保存(文件写出)
Reduce计算层
wc.go
//key为文本中的单词
//values为各个Map处理后得到的单词的个数
func reduceF(key string, values []string) string {
sum :=0
for _,v := range values{
num,err := strconv.Atoi(v) //string转int
if err!=nil{
panic(err)
}
sum+=num //累加
}
return strconv.Itoa(sum) //将int转string返回
}
Reduce计算层则仅仅负责数据的规约,步骤如下:
- 遍历整个values切片
- 将values的数值累加
- 将累加总和作为结果返回
Merge
func (mr *Master) merge() {
kvs := make(map[string]string) //总的数据存放
for i := 0; i < mr.nReduce; i++ {
p := mergeName(mr.jobName, i) //merge文件名生成
file,err :=ioutil.ReadFile(p)
if err != nil {
log.Fatal("Merge: ", err)
}
var jsonObj []KeyValue
err = json.Unmarshal(file,&jsonObj) //json解码
if err != nil{
log.Fatal("Merge: ", err)
}
for _,v:=range jsonObj{
kvs[v.Key] = v.Value
}
}
}
Merge操作便将Reduce操作得到的数据进行合并,完成最后一步工作。
总结
通过这几天短暂的学习,MapReduce模型确实能够极大的利用现有计算资源来打造一个算力强劲的计算机集群,但是本实例中也存在几个局限性:
- 本实例仅在单机中运行
- 操作间数据交换使用文件,在性能上可能会有一定影响
- 任务划分的科学性也应该是性能上应该考虑的问题,集群中计算机算力各不相同的时候,能者多劳,任务的划分应更加合理,才可能避免水桶原理造成的性能上的损失
如有不足之处,恳请提出批评!